Exploring and sharing practical insights on virtualization, cloud technologies, automation, and DevOps. My mission is to empower others to build, automate, and innovate with confidence.
Highly Available ELK (Elasticsearch, Logstash and Kibana) Setup
64 minute read
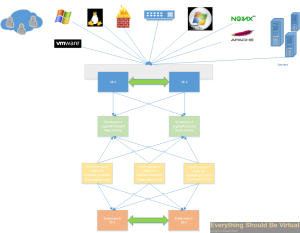
In this post I will be going over how to setup a complete ELK
(Elasticsearch, Logstash and Kibana) stack with clustered elasticsearch
and all ELK components load balanced using HAProxy. I will be setting up
a total of four six servers (2-HAProxy, 2-ELK frontends and
2-Elasticsearch master/data nodes) in this setup however you can scale
the ELK stack by adding additional nodes identical to
logstash-1/logstash-2 for logstash processing and Kibana web interfaces
and adding the additional node info to the HAProxy configuration files
to load balance. You can also scale the Elasticsearch Master/Data nodes
by building out addtional nodes and they will join the cluster.
Acronyms throughout article
ELK - Elasticsearch Logstash Kibana
ES - Elasticsearch
Requirements:
In order for all logstash-elasticsearch clustering to work correctly all
HAProxy nodes and ELK nodes should be on the same subnet (If not you
will need to configure unicast mode for Elasticsearch as multicast is
enabled using these scripts).
Two Ubuntu (12.04LTS/14.04LTS) HAProxy nodes with two NICS each.
(1vCPU and 512MB memory will work)
Two or more Ubuntu (12.04LTS/14.04LTS) nodes to install the ELK stack
frontends. (2vCPU and 2GB memory will work)
Two or more Ubuntu (12.04LTS/14.04LTS) nodes to install the ES
Master/Data nodes. (2vCPU and 4GB of memory will work)
IP Addresses required to set all of this up. (Change to fit your
environment.)
DNS A Record: logstash(with the LB VIP address) (If you use
something other than this name update in each location that logstash is
configured for. I will be providing a script to do this in the near
future.)
LB VIP 10.0.101.60
haproxy-1 10.0.101.61
haproxy-2 10.0.101.62
logstash-1 10.0.101.185
logstash-1 172.16.0.1 (Cluster Heartbeat)
logstash-2 10.0.101.180
logstash-2 172.16.0.2 (Cluster Heartbeat)
es-1 10.0.101.131
es-2 10.0.101.179
If you decide to use different node names than the above list then you
will need to make sure to make changes to the configurations to reflect
these changes.
HAProxy Nodes (haproxy-1, haproxy-2):
Setup both HAProxy nodes identical all the way down to the ELK stack
setup section. The below instructions which have been crossed out are no
longer valid but will remain in the off chance that you would like to
use heartbeat instead of keepalived for your cluster setup.
First thing we need to do is install all of the packages needed.
sudo apt-get install haproxy heartbeat watchdog
```bash
Now we will need to configure networking on each nodes as follows.
(Again modify to fit your environment.)```bash
sudo apt-get install haproxy keepalived
```jinja2
**HAProxy-1 (Primary)**```bash
sudo nano /etc/network/interfaces
```jinja2
Overwrite the contents with the code from below.
<noscript><pre>iface lo inet loopback
auto lo
auto eth0
iface eth0 inet static
address 10.0.101.61
netmask 255.255.255.0
gateway 10.0.101.1
dns-search everythingshouldbevirtual.local
dns-nameservers 10.0.101.110 10.0.101.111 10.0.101.112
auto eth1
iface eth1 inet static
address 172.16.0.1
netmask 255.255.255.0
</pre></noscript><script src="https://gist.github.com/mrlesmithjr/1a52e824f22ced8e6758.js"> </script>
**HAProxy-2 (Failover)**```bash
sudo nano /etc/network/interfaces
```jinja2
Overwrite the contents with the code from below.
<noscript><pre>iface lo inet loopback
auto lo
auto eth0
iface eth0 inet static
address 10.0.101.62
netmask 255.255.255.0
gateway 10.0.101.1
dns-search everythingshouldbevirtual.local
dns-nameservers 10.0.101.110 10.0.101.111 10.0.101.112
auto eth1
iface eth1 inet static
address 172.16.0.2
netmask 255.255.255.0</pre></noscript><script src="https://gist.github.com/mrlesmithjr/c8d756fb927af7f0927d.js"> </script>
We need to allow an interface to be brought online that is not part of
the _/etc/network/interfaces_ configuration so we need to run the
following. This will allow all of our VIP's to come up.
```bash
echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf
```jinja2
Verify that the above setting has been set by running the following on
each node. You should get back the
following `net.ipv4.ip_nonlocal_bind = 1`
```bash
sysctl -p
```bash
Now you will need to restart networking on each node or reboot for the
IP settings from above to be set.
sudo service networking restart
Now we are ready to configure our heartbeat service on each node. We
will do that by setting up the following configuration files on each
node.
```bash
sudo nano /etc/ha.d/ha.cf
```jinja2
Copy the following into ha.cf file.
<noscript><pre>watchdog /dev/watchdog
logfile /var/log/ha-log
debugfile /var/log/ha-debug
deadtime 5
warntime 10
initdead 15
bcast eth1
auto_failback on
node haproxy-1
node haproxy-2
keepalive 2
ping 172.16.0.1
udpport 694</pre></noscript><script src="https://gist.github.com/mrlesmithjr/1e9a5072b668fb5ea839.js"> </script>
```bash
sudo nano /etc/ha.d/authkeys
```jinja2
Copy the following into authkeys (change password to something else).
```bash
auth 3
1 crc
2 sha1 password
3 md5 password
```bash
Now change the permissions of the authkeys as follows.
```bash
sudo chmod 600 /etc/ha.d/authkeys
```sql
Now we will create the haresources file to complete the heartbeat
service setup.
```bash
sudo nano /etc/ha.d/haresources
```jinja2
Copy the following into haresources.
```bash
haproxy-1 IPaddr::10.0.101.60/24/eth0 logstash
```sql
Now we need to configure the keepalived cluster service. All that we
need to do is create _/etc/keepalived/keepalived.conf_
```bash
sudo nano /etc/keepalived/keepalived.conf
```jinja2
And copy the contents from below and save the file. Make sure to modify
the IP addresses to match your environment.
<noscript><pre>vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_1 {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 101 # 101 on master, 100 on backup (Make sure to change this on HAPROXY node2)
virtual_ipaddress {
10.0.101.60 # the virtual IP's
}
track_script {
chk_haproxy
}
}</pre></noscript><script src="https://gist.github.com/mrlesmithjr/9b11490f45c602726f81.js"> </script>
Now you need to start the _keepalived_ service
```bash
sudo service keepalived start
```bash
You can check and make sure that all of your VIP's came up by running
the following. A normal ifconfig will not show them.
```bash
sudo ip a | grep-e inet.*eth0
```jinja2
You should see something similar to below.
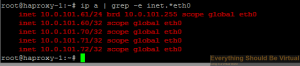
Now we are ready to setup HAProxy for our ELK stack. The final piece of
our setup for frontend load balancer cluster.
```bash
sudo nano /etc/haproxy/haproxy.cfg
```jinja2
Replace all contents in haproxy.cfg with the following code.
<noscript><pre>global
log logstash local0 #Change logstash to your naming
log-send-hostname
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn 4000
defaults
log global
mode http
option httplog
option dontlognull
option redispatch
retries 3
timeout client 35s
timeout server 60s
timeout connect 5s
timeout http-keep-alive 10s
# contimeout 5000# clitimeout 50000# srvtimeout 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
listen stats :9090
balance
mode http
stats enable
stats auth admin:admin
listen logstash-syslog-TCP-514 10.0.101.60:514
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:514 check
server logstash-2 logstash-2:514 check
listen logstash-VMware-TCP-1514 10.0.101.60:1514
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:1514 check
server logstash-2 logstash-2:1514 check
listen logstash-vCenter-TCP-1515 10.0.101.60:1515
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:1515 check
server logstash-2 logstash-2:1515 check
listen logstash-Netscaler-TCP-1517 10.0.101.60:1517
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:1517 check
server logstash-2 logstash-2:1517 check
listen logstash-eventlog-TCP-3515 10.0.101.60:3515
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:3515 check
server logstash-2 logstash-2:3515 check
listen logstash-iis-TCP-3525 10.0.101.60:3525
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:3525 check
server logstash-2 logstash-2:3525 check
listen logstash-redis-TCP-6379 10.0.101.60:6379
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:6379 check
server logstash-2 logstash-2:6379 check
listen elasticsearch-TCP-9200 10.0.101.60:9200
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server logstash-1 logstash-1:9200 check
server logstash-2 logstash-2:9200 check
listen elasticsearch-TCP-9300 10.0.101.60:9300
mode tcp
option tcpka
option tcplog
#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance roundrobin
server es-1 es-1:9300 check
server es-2 es-2:9300 check
listen kibana-http 10.0.101.60:80
mode http
stats enable
stats auth admin:password # Change this to your own username and password!#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance source
option httpclose
option forwardfor except 10.0.101.61 # Change this to 10.0.101.62 (Or IP of second node) when setting up second node
cookie JSESSIONID prefix indirect nocache
server logstash-1 logstash-1:80 check cookie L1
server logstash-2 logstash-2:80 check cookie L2
listen kibana-https 10.0.101.60:8443
mode http
stats enable
stats auth admin:password # Change this to your own username and password!#balance leastconn - The server with the lowest number of connections receives the connection#balance roundrobin - Each server is used in turns, according to their weights.#balance source - Source IP hashed and divided by total weight of servers designates which server will receive the request
balance source#option httpchk
option httpclose
option forwardfor except 10.0.101.61 # Change this to 10.0.101.62 (Or IP of second node) when setting up second node
cookie JSESSIONID prefix indirect nocache
server logstash-1 logstash-1:8080 check cookie L1
server logstash-2 logstash-2:8080 check cookie L2</pre></noscript><script src="https://gist.github.com/mrlesmithjr/5ee958df9c9ad941ac2d.js"> </script>
Now we need to set HAProxy to enabled so it will start.
```bash
sudo nano /etc/default/haproxy
```bash
Change
```bash
ENABLED=0
```bash
to
```bash
ENABLED=1
```bash
Now we should be able to start HAProxy up.
```bash
sudo service haproxy start
```bash
If you see errors similar to below these can be ignored.
```bash
[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'logstash-syslog-514'(needs 'mode http'). Falling back to 'option tcplog'.[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'logstash-syslog-1514'(needs 'mode http'). Falling back to 'option tcplog'.[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'logstash-eventlog'(needs 'mode http'). Falling back to 'option tcplog'.[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'logstash-iis'(needs 'mode http'). Falling back to 'option tcplog'.[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'logstash-redis'(needs 'mode http'). Falling back to 'option tcplog'.[WARNING] 153/132650 (4054) : config : 'option httplog' not usable with proxy 'elasticsearch'(needs 'mode http'). Falling back to 'option tcplog'.[ OK ]```bash
Now one last thing to do based on the fact that HAProxy cannot load
balance UDP ports and not all network devices have the option to send
their syslog data to a TCP port. We will install an instance of Logstash
and setup rsyslog forwarding on each HAProxy node. This instance will
only listen for syslog on the standard UDP/514 port, do some filtering
and join the logstash-elasticsearch cluster as a client and output to
this cluster. be configured to monitor the nginx logs and forward them
back to the logstash cluster using redis. We will be configuring rsyslog
to listen on UDP/514 and forward to the logstash cluster over TCP/514. I
have made this extremely easy by running a script. **However do not
run this until after you have setup your ELK stack nodes below. If you
do set this up prior to building out your ELK nodes then you will need
to restart the logstash service on each of your haproxy nodes.**
If for some reason you need to restart the logstash service you can do
so by running.
```bash
sudo service logstash restart
```bash
So let's setup our logstash instance and configure rsyslog forwarding.
To do so run the following commands in a terminal session on each of
your HAProxy nodes.
```bash
sudo apt-get install git
cd ~
git clone https://github.com/mrlesmithjr/Logstash_Kibana3
chmod +x ./Logstash_Kibana3/Cluster_Setup/Logstash-HAProxy-Node.sh
sudo ./Logstash_Kibana3/Cluster_Setup/Logstash-HAProxy-Node.sh
```sql
If you copied the haresources file exactly from above then Logstash
will only be running on the active cluster node and will start on the
failover node when a failover occurs.
Now HAProxy node1 is complete make sure to do all of the above on your
HAProxy node2 and make sure to change the priority as noted in the
_keepalived.conf_ file. Once you have completed HAProxy node2 continue
onto the next section of setting up your ELK stack. You could also clone
the first node to create the second node but if you do; make sure to
make the proper change in keepalived.conf and haproxy.cfg as above.
**ES (Elasticsearch Master/Data Nodes (es-1, es-2):**
Now we will be setting up our two nodes to build our Elasticsearch
cluster and again I have a script to do this. These nodes will only be
Master/Data nodes. They will not be doing any logstash processing. They
will purely be used to maintain the cluster and provide redundancy.
These nodes will not be exposed to the HAProxy Load Balancers; Only our
ELK nodes below will be. These nodes will process all of the data that
our frontend ELK nodes send back to be ingested, indexed and etc. For
now we will only be setting up two ES Master/Data nodes; however you can
build out as many as you like and use this same script each time for
each additional node (If you add more than two you will want to adjust
the following parameter in /etc/elasticsearch/elasticsearch.yml to
ensure you do not experience a split-brain ES cluster. You will set the
value to n/2+1 where n=number of nodes. So for example with just two
nodes it would be 1 (or not set); whereas with 3 the value would be 2
(3/2+1=2)). Just make sure that every node-name is unique and has a DNS
record associated with it.
_discovery.zen.minimum_master_nodes: 2_
So let's get these nodes up and running.
On your new ES nodes run the following script on each to get them
running.
```bash
sudo apt-get install git
cd ~
git clone https://github.com/mrlesmithjr/Logstash_Kibana3
chmod +x ./Logstash_Kibana3/Cluster_Setup/Logstash-ES-Cluster-Master-data-node.sh
sudo ./Logstash_Kibana3/Cluster_Setup/Logstash-ES-Cluster-Master-data-node.sh
```bash
Once these are up and running your new ES cluster (logstash-cluster)
should be ready to go. However you will want to modify your Java Heap
Size to 50% of the installed memory. So if you installed per the
requirements you will want to adjust the ES_HEAP_SIZE to 2g because by
default it will be at 1g. And it is commented out by default.
```bash
sudo nano /etc/init.d/elasticsearch
```jinja2
change
```bash
#ES_HEAP_SIZE=1g```bash
to
```bash
ES_HEAP_SIZE=2g
```bash
Now proceed onto setting up the frontend ELK nodes.
**ELK (Elasticsearch, Logstash and Kibana) Nodes (logstash-1, logstash-2):**
Now we are ready to set up our ELK frontend nodes and again I have a
script to make this process repeatable and simple. For now we will only
be setting up two ELK nodes; however you can build out as many as you
like and use this same script each time for each additional node. Just
make sure that every node-name is unique and has a DNS record associated
with it.
So to get started all you need to do is run the following on a fresh
Ubuntu 12.04LTS/14.04LTS server. And let the script setup your ELK node.
Again this script will install Elasticsearch and join the
"logstash-cluster" with master capabilities and as a data node as
a client node, install Logstash with many different filtering patterns
and inputs; as well as join the "logstash-cluster" as a client node
(From logstash output - so yes; 2 instances per ELK node will show as
clients in the ES cluster) to output all logs to and install the Kibana3
webUI configured to read from the "logstash-cluster". These ELK nodes
will do all of the heavy lifting for logstash processing as well as
servicing Kibana requests meanwhile keeping that load off of the ES
Master/Data nodes from above (allowing them to do nothing more than
churn data).
So all that is left to do once this is done is to start pointing your
network devices to the HAProxy VIP **_(10.0.101.60 or logstash)_**for
syslog and watch the data start flowing in.```bash
sudo apt-get install git
cd ~
git clone https://github.com/mrlesmithjr/Logstash_Kibana3
chmod +x ./Logstash_Kibana3/Cluster_Setup/Logstash-ELK-ES-Cluster-client-node.sh
sudo ./Logstash_Kibana3/Cluster_Setup/Logstash-ELK-ES-Cluster-client-node.sh
```bash
Once this has been completed make sure to go back up at the end of the
HAProxy setup and install the logstash instance on each node. Once
that has been completed you can begin to test out with only one ELK node
or you can build out a few more ELK nodes if you like. I would at least
start with two to get the full benefit of this setup.
**\*\***NOTE\*\*
If you used different naming for your VIP hostname other than logstash
you will need to modify the following file on on each of your ELK Client
nodes for the Kibana web interface to connect to ES correctly.
You can do that by doing the following and replacing logstash with your
viphostname used for your setup...(example myloghostname)
Edit /usr/share/nginx/html/kibana/config.js and change
<http://logstash:9200> to <http://yourviphostname:9200>
```bash
sudo nano /usr/share/nginx/html/kibana/config.js
```jinja2
Or you can do the following but replace yourviphostname with the actual
VIP hostname used for your setup
```bash
sed-i-e's|^elasticsearch: "http://logstash:9200",|elasticsearch: "http://yourviphostname:9200",|' /usr/share/nginx/html/kibana/config.js
```jinja2
Now all that is left to do is configure your network devices to start
sending their syslogs to the HAProxy VIP and if your device supports
sending via TCP, **_use it_**. Why use it? Because you will benefit from
the load balancing of the TCP connections and there will not be any lost
events (UDP - Best effort, fast!, TCP - Guaranteed, slower; but this
type of setup will bring great results!)
Reference the port list below on configuring some of the devices that
are pre-configured during the setup.
**Port List**
_TCP/514_ Syslog (Devices supporting TCP)
_UDP/514_ Syslog (Devices that do not support TCP - These are captured
on the HAProxy nodes and shipped to logstash using redis)
_TCP/1514_ VMware ESXi
_TCP/1515_ VMware vCenter (Windows install or appliance)(For Windows
install use NXLog from below in device setup)(For appliance reference
device setup below)
_TCP/3515_ Windows Eventlog (Use NXLog setup from below in device
setup)
_TCP/3525_ Windows IIS Logs (Use NXLog setup from below in device setup)**Device Setup**
For _Windows_ (IIS,Eventlog and VMware vCenter logging)install [nxlog ](http://nxlog.org/ "http\://nxlog.org/")and use the
following nxlog.conf file below to replace everything in C:\\Program
Files (x86)\\nxlog\\conf\\nxlog.conf\
<noscript><pre>## Please set the ROOT to the folder your nxlog was installed into,
## otherwise it will not start.#define ROOT C:\Program Files\nxlog
define ROOT C:\Program Files (x86)\nxlog
define ROOT_STRING C:\Program Files (x86)\\nxlog
Moduledir %ROOT%\modules
CacheDir %ROOT%\data
Pidfile %ROOT%\data\nxlog.pid
SpoolDir %ROOT%\data
LogFile %ROOT%\data\nxlog.log
# Enable json extension
<Extension json>
Module xm_json
</Extension>
<Extension syslog>
Module xm_syslog
</Extension>
<Processor buffer1>
Module pm_buffer
MaxSize 1024
Type Mem
WarnLimit 512
</Processor>
<Processor buffer2>
Module pm_buffer
MaxSize 1024
Type Mem
WarnLimit 512
</Processor># Nxlog internal logs
<Input internal>
Module im_internal
Exec $EventReceivedTime= integer($EventReceivedTime) / 1000000; to_json();
</Input># Windows Event Log
<Input eventlog># Uncomment im_msvistalog for Windows Vista/2008 and later
Module im_msvistalog
# Uncomment im_mseventlog for Windows XP/2000/2003# Module im_mseventlog
Exec $EventReceivedTime= integer($EventReceivedTime) / 1000000; to_json();
</Input># Select the input folder where logs will be scanned# Create the parse rule for IIS logs. You can copy these from the header of the IIS log file.# Uncomment Extension w3c for IIS logging#<Extension w3c># Module xm_csv# Fields $date, $time, $s-ip, $cs-method, $cs-uri-stem, $cs-uri-query, $s-port, $cs-username, $c-ip, $csUser-Agent, $cs-referrer, $sc-status, $sc-substatus, $sc-win32-status, $time-taken# FieldTypes string, string, string, string, string, string, integer, string, string, string, string, integer, integer, integer, integer# Delimiter ' '#</Extension># Convert the IIS logs to JSON and use the original event time# Uncomment IIS_IN section if logging for IIS logging#<Input IIS_IN># Module im_file# File "C:\\inetpub\\logs\\LogFiles\\W3SVC2\\u_ex*"# SavePos TRUE# Exec if $raw_event =~ /^#/ drop(); \# else \# { \# w3c->parse_csv(); \# $EventTime = parsedate($date + " " + $time); \# $SourceName = "IIS"; \# $Message = to_json(); \# }#</Input># Uncomment vCenter_vpxd section for Windows vCenter logging #<Input vCenter_vpxd># Module im_file# File "C:\ProgramData\VMware\VMware VirtualCenter\Logs\vpxd-*.log"# Exec $Message = $raw_event;# SavePos TRUE# Recursive TRUE#</Input># Uncomment vCenter_vpxd_alert section for Windows vCenter logging#<Input vCenter_vpxd_alert># Module im_file# File "C:\ProgramData\VMware\VMware VirtualCenter\Logs\vpxd-alert-*.log"# Exec $Message = $raw_event;# SavePos TRUE# Recursive TRUE#</Input>
<Processor t>
Module pm_transformer
OutputFormat syslog_rfc3164
</Processor># Change Host below to match your naming
<Output out>
Module om_tcp
Host logstash
Port 3515
</Output># Change Host below to match your naming# Uncomment IIS_Out section if using IIS logging#<Output IIS_Out># Module om_tcp# Host logstash# Port 3525#</Output># Change Host below to match your naming# Uncomment vCenter_out section for vCenter logging#<Output vCenter_out># Module om_tcp# Host logstash# Port 1515#</Output># Output routing
<Route 1>
Path internal, eventlog => buffer1 => out
</Route># Uncomment Route 2 if using IIS logging#<Route 2># Path IIS_In => IIS_Out#</Route># Uncomment Route 3 for vCenter logging#<Route 3># Path vCenter_vpxd, vCenter_vpxd_alert => t => vCenter_out#</Route></pre></noscript><script src="https://gist.github.com/mrlesmithjr/cf212836b9ce162373ed.js"> </script>
For _VMware vCenter appliance_ do the following from the appliance
console.
```bash
vi /etc/syslog-ng/syslog-ng.conf
```ruby
Now add the following to the end of the syslog-ng.conf file
```bash
source vpxd {
file("/var/log/vmware/vpx/vpxd.log" follow_freq(1) flags(no-parse));
file("/var/log/vmware/vpx/vpxd-alert.log" follow_freq(1) flags(no-parse));
file("/var/log/vmware/vpx/vws.log" follow_freq(1) flags(no-parse));
file("/var/log/vmware/vpx/vmware-vpxd.log" follow_freq(1) flags(no-parse));
file("/var/log/vmware/vpx/inventoryservice/ds.log" follow_freq(1) flags(no-parse));};## Remote Syslog Host
destination remote_syslog {
tcp("logstash" port (1515));};### Log vCenter Server vpxd log remotely
log {source(vpxd);
destination(remote_syslog);};```bash
Now restart syslog-ng
```bash
/etc/init.d/syslog restart
```bash
For _Linux_ (Ubuntu, etc.) I prefer rsyslog as it is installed by
default on most.
```bash
sudo nano /etc/rsyslog.d/50-default.conf
```text
Now add the following to the end of this file
```bash
*.* @@logstash
Note the ”@@” this means use TCP; whereas “@” means use UDP.
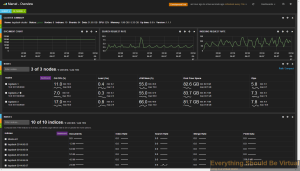
Now that your setup is complete you can browse to the Kibana webUI by
using your browser of choice
and go here.
You should see some logs showing up here now but the view is not that
great or usable so you will need to start building how you want your
dashboard to look. Or you can use some of the dashboards I have created
by clicking the load folder at the top right and go to advanced and
enter the gist number or url by using the gist url’s below (copy and
paste the https://url). Once you load the dashboard make sure to save it
or it will be gone once you browse away.
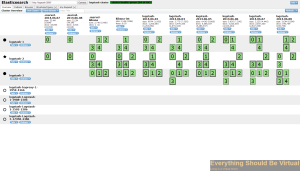
To view your HAProxy stats
go here.
(Login with admin/admin)
So there you have it. A highly available ELK setup which also allows us
to scale out extremely easy and is repeatable.
While I have been going through this setup and testing out different
components brought to light many other options for HAProxy and the ideas
behind this post so stay tuned to more soon. As well as I will be
providing a visio drawing of the layout. I am also working on some
scripts to setup a proxy (nginx) in front of kibana for ssl password
protection to login and to redirect ES queries through the proxy; as
well as some scripts to do IPTables firewall configurations to tighten
down access into the ES nodes forcing access through the nginx proxy and
HAProxy Load Balancers mitigating access directly to an ES node. This
will all be in a follow up post very soon.
Walk into almost any enterprise and you will find the same thing. Three teams, three tools, no shared view. The networking team has stood up Nautobot or NetB...
It has been a little over three years since I last wrote anything here, and the biggest change in that time is not a tool or a platform. It is what I do day ...
Recently I had the privilege to attend NFD 24
in which DriveNets presented. I had never heard of them
until this event. Which I am shaming myself for because...
Comments